




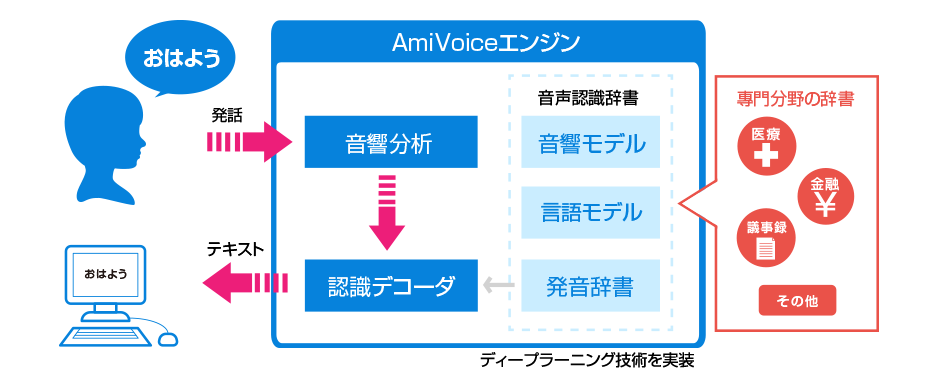
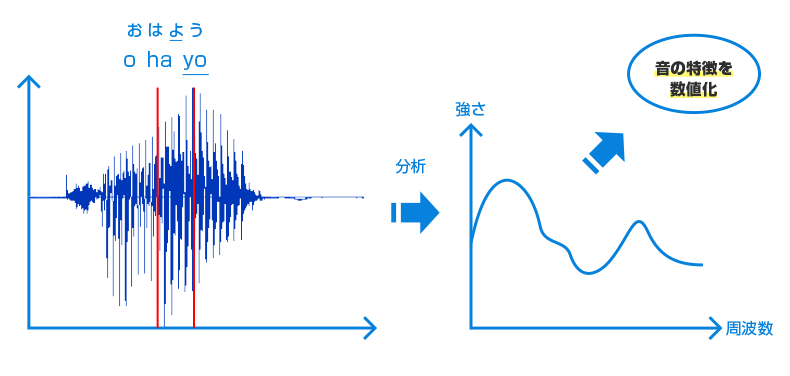
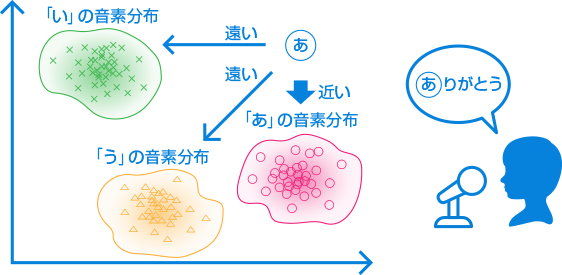
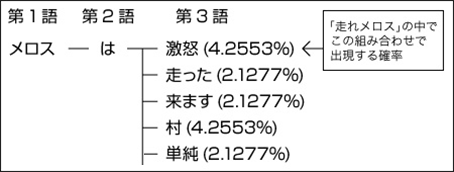
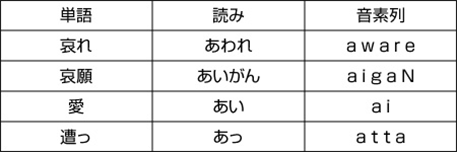




-
議事録・書き起こし
-
コンタクトセンター
-
医療
-
開発向けAPI・SDK
-
製造・物流
-
商談記録・報告業務
-
建設・不動産
-
AI対話
-
マイクデバイス








